Ресурс на наличие дублей страниц. Внутренние дубли страниц – чем опасны, как найти и обезвредить. Как убрать дубли страниц
— , который работает над продвижением сайта. Он может создать две одинаковые главные страницы, которые отличаются адресами.
Алгоритмы поисковых систем работают автоматически, и нередко бывает так, что дубль воспринимается системой более релевантным, чем страница-оригинал. В результате выдача будет выдавать не оригинал, а его дубль. В свою очередь, дубль обладает другими параметрами, что позже скажется на пессимизации сайта.
Существуют различные способы поиска и проверки дублированных страниц. От исполнителя они требуют разной степени знаний CMS, а также понимания того, каким образом работает поисковый индекс. Попробуем показать Вам наипростейший способ для проверки сайта на дубли страниц. Сразу отметим, что данный способ является не очень то и точным. Но, в тоже время подобный способ позволяет совершать поиск дублей страниц сайта, и не занимает много времени.
Теперь давайте посмотрим, как сделать то же самое только в системе Google. В принципе, процедура ничем не отличается, потребуется совершить такие же действия, как и в Яндексе.
Поисковая система Яндекс сразу же предоставляет список дублей, а вот в Гугле, чтобы увидеть дубли, необходимо будет дополнительно нажать «Показать скрытые результаты», поскольку зачастую на экран выводится оригинал страницы.
С картинки видно что, в основной выдаче находится 1 страница сайта, и она же и является оригиналом. Но в индексе существуют другие страницы, являющиеся дублями. Чтобы их увидеть, нужно нажать на ссылку “Показать скрытые результаты”. В результате мы получаем список, где под номером 1 находится оригинал, а дальше уже размещены дубликаторы. Частенько дубли придется чистить вручную.
Как проверить сайт на дубли страниц
В ниже приведенной статье мы сегодня попытаемся рассмотреть много вопросов, касающихся проблемы дублирования страниц, что становится причиной возникновения дублей, как от этого избавиться, и вообще, почему нужно избавляться от дубликатов.
Для начала давайте разберемся, что кроется под понятием «дублирование контента». Нередко случается, что некоторые страницы могут содержать частично или в полной мере одинаковый контент. Понятно, что каждая отдельная страница имеет свой собственный адрес.
Причины возникновения дублей:
— владельцы сайта сами создают дубли для определенных целей. Допустим, это может быть страница для печати, которая позволяет посетителю коммерческого сайта скопировать необходимую информацию по определенному товару или услуге.
— они генерируются движком интернет-ресурса, поскольку это заложено в их теле. Определенное количество современных СMS могут выдавать похожие страницы с различными URL, которые размещены на разных директориях.
— ошибки вебмастера, который работает над продвижением сайта. Он может создать две одинаковые главные страницы, которые отличаются адресами.
— изменение структуры сайта. При создании нового шаблона с иной системой URL, новые страницы, вмещающие старый контент, получают другие адреса.
Мы перечислили возможные причины возникновения четких дублей, но существуют еще и нечеткие, то есть частичные. Зачастую подобные страницы имеют схожую часть шаблона ресурса, но контент их немного отличается. Подобными дублями могут быть страницы сайта, которые имеют одинаковый результат поиска или же отдельный элемент статьи. Чаще всего, такими элементами становятся картинки.
От дублированных страниц необходимо избавляться. Нет, это не вирус, но он также со временем разрастается, правда, это зависит не от самого ресурса. Дубли зачастую становятся последствием непрофессионального вебмастера, или же результатом неправильного кода сайта.
Важно знать, что дубли могут нанести ресурсу немалый ущерб. К каким же последствиям может привести наличие дублей на сайте? Во-первых, это ухудшение индексации ресурса. Согласитесь, что подобная ситуация не очень то обрадует владельца сайта. В то время как на продвижение ресурса постоянно тратятся финансы и время, ресурс начинает терять свою популярность за несколько дней. Глубина проблемы будет зависеть от количества дублей.
Бывает так, что главная страница может иметь пару-тройку дубликатов. С блогам дело обстоит несколько по-другому. Благодаря replytocom может быть огромное количество дублей из-за копирования комментариев. Получается, что чем популярнее блог, тем больше дубликатов он будет содержать. В свою очередь, системы поиска, в особенности Google, из-за наличия таких вот дублей занижает позиции ресурса.
Алгоритмы поисковых систем работают автоматически, и нередко бывает так, что дубль воспринимается системой более релевантным, чем страница-оригинал. В результате выдача будет выдавать не оригинал, а его дубль. В свою очередь, дубль обладает другими параметрами, что позже скажется на пессимизации сайта.
Что же у нас получается? Дублированные страницы становятся реальной помехой в индексации сайта, а также причиной неверного выбора поисковой системы релевантной страницы, снижают влияние естественных ссылок. Помимо этого, дубли неправильно распределяют внутренний вес, снижая силу продвигаемых страниц, а также меняя поведенческие показатели.
Как проверить сайт на дубли страниц?
Существуют различные способы поиска и проверки дублировааных страниц. От исполнителя они требуют разной степени знаний CMS, а также понимания того, каким образом работает поисковый индекс. Попробуем показать Вам наипростейший способ для проверки сайта на дубли страниц. Сразу отметим, что данный способ является не очень то и точным. Но, в тоже время подобный способ позволяет совершать поиск дублей страниц сайта, и не занимает много времени.
Для поиска и проверки собственного ресурса на наличие дубликатов, следует просто ввести в расширенный поиск поисковой системы специальный запрос. Если Вы используете расширенную версию поиска в Яндекс, можно получить довольно подробные результаты благодаря тому, что здесь имеется возможность вводить уточняющие параметры для запроса.
Нам понадобится адрес ресурса и та часть текста, дубликат которого мы хотим найти. Для этого нам потребуется на своей странице выделить фрагмент текста, после чего в расширенном поиске системы Яндекс ввести скопированный текст и адрес сайта. Теперь необходимо нажать кнопку «Найти», после чего система начнет поиск.
Результаты будут выведены не в обычном режиме. Список сайтов будет содержать только заголовки и сннипеты нашего ресурса. В том случае, когда система выдает единственный результат, это значит, что дубликатов данной страницы нет. А вот при выдаче нескольких результатов придется поработать.
Теперь давайте посмотрим, как сделать то же самое только в системе Google. В принципе, процедура ничем не отличается, потребуется совершить такие же действия, как и в Яндексе.
Расширенный поиск позволяет легко находить все дубликаты по определенному фрагменту текста. Безусловно, что таким способом мы не получим дублей страниц, которые не содержат указанного текста. Нужно сказать что, если дубль был создан искривленным шаблоном, то он только показывает, например, картинку из оригинала на другой странице. Разумеется, что если текста дубликат не содержит, то выше описанным способом его определить не удастся. Для этого необходим другой способ.
Второй способ также отличается своей простотой. Надо воспользоваться специальным оператором и запросить индексацию своего сайта, или же его отдельных страниц. После этого придется вручную смотреть выдачу в поиске дублей.
Правила синтаксиса необходимого запроса:
В той ситуации, когда в поиск вводится просто адрес главной страницы, нам показан список проиндексированных страниц с помощью поискового робота. А вот, если укажем адрес конкретной страницы, то система выводит уже проиндексированные дубли данной страницы.
Поисковая система Яндекс сразу же предоставляет список дублей, а вот в Гугле, чтобы увидеть дубли, необходимо будет дополнительно нажать «Показать скрытые результаты», поскольку зачастую на экран выводится оригинал страницы.
Как видно на картинке, в основной выдаче у нас находится одна страница сайта и она же является оригиналом. Но в индексе есть и другие страницы, которые являются дублями. Чтобы их увидеть, нужно нажать на ссылку “Показать скрытые результаты”. В результате мы получаем список, где под номером 1 находится оригинал, а дальше уже размещены дубликаторы. Частенько дубли придется чистить вручную.
Сегодня мы будем говорить о дублировании контента, а точнее о методах поисках дублей страниц на вашем ресурсе. Проблема дублирования в современном интернете стоит остро, так как если у вас имеются дубли страниц на сайте, вы можете попасть под санкции поисковых систем.
И так первое, что нам необходимо знать это “что такое дублирование контента (дубли страниц) ” и какие бывают их виды, а потом мы уже будем искать пути борьбы с ними.
Дублирование контента – это отображение одного и того же текста на разных страницах сайта (на разных адресах). Дубли страниц на сайте бывают двух видов:
- Полные дубли;
- Неполные (частичные) дубли;
Полные дубли – это когда одна страница, в полной мере отображает содержимое другой и при этом имеет другой адрес.?&cat=10&product=25 и https://сайт/?product=25&cat=10
Неполные дубли – это частичное отображение текста страницы на другой. Это например новостная лента в блогах или текст в сайдбарах. Наиболее часто они встречаются в интернет-магазинах и сайтах где публикуются анонсы, новости.
Как определить дубли страницы на сайте.
Ниже я приведу методы которые используются для определения дублей. Ничего сложного здесь нету, только необходимо немного времени и терпения.
- Поисковая выдача Yandex;
- Поисковая выдача Google;
- Страница открывается со слешем “/” и без;
- Страница открывается с www и без www;
1. Начинаем с первого метода, переходим в аккаунт Google–вебмастер. Дальше переходим на вкладку “Вид в поиске либо Оптимизаци ” и выбираем “Оптимизация HTML ”. На этой странице можно найти и посмотреть все похожие мета-описания и заголовки title.
Google Webmaster определяем дубли страниц на сайте.
Этот метод отлично подойдет для определения полных дублей, частичные дубли с помощью этого метода определить не возможно.
2. Далее рассматриваем как можно определить дубли с помощь поисковой выдачи Yandex. Переходим в поисковую систему и вводим часть текста, при этом обворачиваем его в “кавычки” для того что бы получить точное вхождение фразы.

 Yandex — проверяем дубли страниц
Yandex — проверяем дубли страниц Если в выдаче появилась только одна страница оригинал, это отлично – значит дублей нету, если же появилось пару страниц, значит имеются дубли которые необходимо удалить.
3. С помощью поисковой системы Google, определять дубли страниц на сайте, можно также, как и в Yandex. Только при этом необходимо в поисковую строку ввести запрос site:moysite.ru -site:moysite.ru/&, где фразу moysite.ru, заменяем на адрес своего сайта. Если в выдаче нашло только один ваш сайт значит дублей нету, если несколько, необходимо предпринимать меры борьбы с дублированием.
4. Дублирование также может бить если вы используете . Система может генерировать автоматические ссылки которые будут открываться как со слешем “/” так и без.?&cat=10&product=25, вы можете проверить открывается ли этот адрес со слешем в конце “/” https://сайт/?&cat=10&product=25/. Если открывается и не перенаправляет () на выше приведенную страницу, то это дубль страница. Если перенаправляет все работает нормально и можно не беспокоится.
5. Определяем зеркала главной страницы сайта. Аналогично выше описанному методу, пробуем добавлять www или убирать спереди адреса сайта. Если заходит и по одному и по другому адресу, то у вас имеются дубли главной страницы и необходимо их склеить и выбрать главное зеркало сайта.
Ищите дублируемый контент на своем ресурсе, так как это может привести к плохим последствиям. Если Яндекс еще более лояльно относится к дублям, то Google очень сильно наказывает за это и накладывает . Дубли страниц это грубо говоря мусор интернета, а поисковые системы не любят мусор так как он кушает много ресурсов. Поэтому советую устранять эти проблемы еще до индексации статьи поисковой системой.
Сегодня мы поговорим о дублях. А именно - что такое дубли страниц на сайте, чем они грозят продвижению, как их найти и убрать.
Что такое дубли страниц на сайте?
Дубли - это страницы с частично или полностью совпадающим контентом, но доступные по разным URL-адресам. Принято их классифицировать как четкие и нечеткие. Примером четких могут послужить зеркала главной страницы сайта:
site.ru
www.site.ru
site.ru/index.php
А нечетких - большие сквозные для всего ресурса участки текста:
Чем опасны дубли страниц?
1. Перескоки релевантных страниц в поисковой выдаче. Самая распространенная проблема, заключающаяся в том, что поисковая система не может однозначно определить, какой из документов следует показывать в выдаче по запросу, тематике которого они удовлетворяют. Как итог - broser rank и поведенческая информация размазываются по дублям, позиции постоянно скачут и далеко не в положительную сторону.
2. Снижение уникальности контента сайта. Ну, тут всё очевидно - идет снижение процента страниц с уникальным контентом, что не может не оказывать негативного влияния на его ранжирование.
Откуда берутся дубли страниц?
1. CMS. Очень популярная причина, берущая своё начало в несовершенстве работы используемой системы управления. Тривиальная ситуация для примера - когда одна запись на сайте принадлежит к нескольким категориям, чьи алиасы входят в URL самой записи. В итоге мы получаем откровенные дубли, например:
site.ru/category1/post/
site.ru/category2/post/
2. Служебные разделы. Тоже можно отнести к несовершенству функционирования CMS, но из-за распространенности проблемы, выношу её в отдельный пункт. Особенно тут грешат Joomla и Birix. Например, какая-либо функция на сайте (авторизация, фильтрация, поиск и т.д.) плодит параметрические адреса, имеющие идентичный контент относительно страницы без параметров в урле. Например:
site.ru/page.php
site.ru/page.php?ajax=Y
3. Человеческий фактор. Сюда можно отнести всё то, что является порождением рук человеческих:
- Упомянутые ранее большие сквозные участки текста.
- Сквозные статические блоки.
- Банальное дублирование статей.
По второму пункту хотелось бы уточнить, что тут речь тут идет в первую очередь про код. На этот счет идет много дебатов, но я говорю абсолютно точно - большие участки сквозного кода - очень плохо. У меня минимум 3 кейса в практике было, когда сокрытие от роботов сквозняков увеличивало индексацию сайта с 20 до 60 тысяч страниц в течении всего одного-двух месяцев. Но тут банального
4. Технические ошибки. Что-то среднее между несовершенством работы CMS и человеческим фактором. Первый пример, который приходит в голову, имел место быть на системе Opencart, когда криво поставленная ссылка привела к зацикливанию:
site.ru/page/page/page/page/../..
Как найти дубли страниц на сайте?
Легче и надежнее всего это будет сделать, пройдя следующие 3 этапа.
1. Программная проверка сайта на дубли страниц. Берем NetPeak Spider, Screaming Frog SEO Spider или любую другую из подобных софтин для внутреннего анализа и сканируем сайт. Затем сортируем, например, по метазаголовкам, и обращаем внимание на их совпадение или полное отсутствие. Совпадение - повод для проверки этих страниц вручную, а отсутствие метаинформации - один из вероятных признаков технического раздела, который лучше закрыть от индексации.

2. 301 редирект. Этот вариант подойдет вам, если копии носят точечный характер и вы не хотите их закрывать от индексации по той или иной причине (например, на них уже кто-то успел поставить внешнюю ссылку). В таком случае просто настраиваем 301 редирект с дубля на основную страницу и проблема решена.
3. Link rel="canonical".
Это является неплохим решением для описанной выше ситуации, когда один и тот же пост доступен по разным урлам. Для каждого такого поста внедряется в код тег вида
Данный тег программно внедряется для каждого поста и далее пусть у него будет хоть 100 урлов - на всех них в коде будет рекомендация для поисковой системы, какой урл вы советуете индексировать, а на какие не обращать внимания (на страницы, чей собственный url и url в link rel="canonical" не совпадают).
4. Google Search Console. Малопопулярный, но, тем не менее, работающий приём, к которому мы можем обратиться в разделе «Сканирование» - «Параметры URL» из Google Search Console.

Добавляя параметры в эту таблицу, мы можем сообщить поисковому роботу, что страницы ними никак не изменяют содержимого, а потому их можно не индексировать. Но, конечно, возможны и другие варианты, при которых содержимое раздела при включении параметра в адрес «перемешивается», оставаясь, однако, при этом неизменным по своему составу (например, сортировка по популярности записей в категории).
Указав об этом в данном разделе, мы тем самым поможем Google лучше интерпретировать сайт в процессе его сканирования. Сообщив о предназначении параметра в URL, вопрос об индексации таких страниц лучше оставить «На усмотрение робота Googlebot&rauqo;.

Часто задаваемые вопросы
Многостраничные разделы (пагинация) - дубли или нет? Закрывать ли от индексации?
Нет, не нужно их закрывать ни от индексации, ни ставить rel="canonical" на первую страницу раздела, так как они имеют уникальный относительно друг-друга контент, а потому не являются дублями. Поисковые системы прекрасно умеют распознавать пагинацию, ну а для пущей надежности достаточно будет снабдить их элементами микроразметки rel="next" и rel="prev". Например:
Урлы с хештегами (#) - дубли или нет? Удалять ли их?
Нет. Поисковая система по умолчанию не индексирует страницы с # в адресе, так что по этому поводу волноваться не надо.
Вот, наверно, и всё. Вопросы?
Мы выпустили новую книгу «Контент-маркетинг в социальных сетях: Как засесть в голову подписчиков и влюбить их в свой бренд».
![]()
Дубли страниц – это идентичные друг другу страницы, находящиеся на разных URL-адресах. Копии страниц затрудняют индексацию сайтов в поисковых системах.
Что такое дубли страниц на сайте
Дубли могут возникать, когда используются разные системы наполнения контентом. Ничего страшного для пользователя, если дубликаты находятся на одном сайте. Но поисковые системы, обнаружив дублирующиеся страницы, могут наложить фильтр\понизить позиции и т. д. Поэтому дубли нужно быстро удалять и стараться не допускать их появления.
Какие существуют виды дублей
Дубли страниц на сайте бывают как полные, так и неполные.
- Неполные дубли – когда на ресурсе дублируются фрагменты контента. Так, например, и разместив части текста в одной статье из другой, мы получим частичное дублирование. Иногда такие дубли называют неполными.
- Полные дубли – это страницы, у которых есть полные копии. Они ухудшают ранжирование сайта.
Например, многие блоги содержат дублирующиеся страницы. Дубли влияют на ранжирование и сводят ценность контента на нет. Поэтому нужно избавляться от повторяющихся страниц.
Причины возникновения дублей страниц
- Использование Системы управления контентом
(CMS) является наиболее распространённой причиной возникновения дублирования страниц. Например, когда одна запись на ресурсе относится сразу к нескольким рубрикам, чьи домены включены в адрес сайта самой записи. В результате получаются дубли страниц: например:
wiki.site.ru/blog1/info/
wiki.site.ru/blog2/info/ - Технические раздел
ы. Здесь наиболее грешат Bitrix и Joomla. Например, одна из функций сайта (поиск, фильтрация, регистрация и т.д.) генерирует параметрические адреса с одинаковой информацией по отношению к ресурсу без параметров в URL. Например:
site.ru/rarticles.php
site.ru/rarticles.php?ajax=Y - Человеческий фактор . Здесь, прежде всего, имеется ввиду, что человек по своей невнимательности может продублировать одну и ту же статью в нескольких разделах сайта.
- Технические ошибки
. При неправильной генерации ссылок и настройках в различных системах управления информацией случаются ошибки, которые приводят к дублированию страниц. Например, если в системе Opencart криво установить ссылку, то может произойти зацикливание:
site.ru/tools/tools/tools/…/…/…
Чем опасны дубли страниц
- Заметно усложняется оптимизация сайта в поисковых системах. В индексе поисковика может быть много дублей одной страницы. Они мешают индексировать другие страницы.
- Теряются внешние ссылки на сайт. Копии усложняют определение релевантных страниц.
- Появляются дубли в выдаче. Если дублирующий источник будет снабжаться поведенческими метриками и хорошим трафиком, то при обновлении данных она может встать в выдаче поисковой системы на место основного ресурса.
- Теряются позиции в выдаче поисковых систем. Если в основном тексте имеются нечёткие дубли, то из-за низкой уникальности статья может не попасть в SERP. Так, например часть новостей, блога, поста, и т. д. могут быть просто не замечены, так как поисковый алгоритм их принимает за дубли.
- Повышается вероятность попадания основного сайта под фильтр поисковых систем. Поисковики Google и Яндекс ведут борьбу с неуникальной информацией, на сайт могут наложить санкции.
Как найти дубли страниц
Чтобы удалить дубли страниц, их сначала надо найти. Существует три способа нахождения копий на сайте.

Как убрать дубли страниц
От дублей нужно избавляться. Необходимо понять причины возникновения и не допускать распространение копий страниц.
- Можно воспользоваться встроенными функциями поисковой системы. В Google используйте атрибут в виде rel="canonical". В код каждого дубля внедряется тег в виде
- Запретить индексацию страниц можно в файле robots.txt. Однако таким путём не получится полностью устранить дубли в поисковике. Ведь для каждой отдельной страницы правила индексации не провпишешь, это сработает только для групп страниц.
- Можно воспользоваться 301 редиректом. Так, роботы будут перенаправляться с дубля на оригинальный источник. При этом ответ сервера 301 будет говорить им, что такая страница более не существует.
Дубли влияют на ранжирование. Если вовремя их не убрать, то существует высокая вероятность попадания сайта под фильтры Panda и АГС.
Мы разговаривали про дубли страниц сайта replytocom. Напомню суть прошлой статьи. Она в том, то не следует делать закрытым в Роботсе путь чему-либо на вашем блоге. Желательно наоборот, роботс сделать открытым, чтобы робот зашел, посмотрел, увидел тег и не стал индексировать дубли страниц.
Если же данные копии страниц будут закрыты, данный робот скорее всего подобные дубли наоборот проиндексирует. Желательно это запомнить! Далее давайте вспомним, как мы искали копии реплитоком в поисковике Гугл. Я напомню:
site:ваш сайт replytocom , т.е. на примере моего это будет выглядеть site:сайт replytocom
Как искать дубли страниц на вашем блоге
Отлично. Сейчас мы поищем прочие копии страничек, а подробнее копии: feed, category, tag, comment-page, page, trackback, attachment_id, attachment
Их поиск проводим похожим образом, как мы искали дубли страниц реплитоком. Делаем все подобным образом, а именно зайдем в и внесем в поисковик любой блог, например site:realnodengi.ru feed

Нажав «Показ скрытых результатов» мы увидим:

22 дубля страницы. Что значит feed? Это непонятный отросток в конце адреса статьи. Для любого вашего поста жмете ctr + u и скорее всего увидите ссылочку feed в конце. Другими словами, подобные ссылки необходимо удалять. Давайте войдем в роботс данного сайта, мы увидим:

То есть то, что нам не нужно . Что же нам делать, подобные запрещения в роботсе желательно удалить. Что бы робот на них не заходил и не индексировал их на «всякий случай».
Отлично! Мы сделали проверку страничек feed.
Возьмём другой сайт, например reall-rabota.ru и вставим page. У нас получится site:reall-rabota.ru page:

Мы видим, что на данном сайте присутствует 61 дубль страниц page. От них необходимо избавляться. Я надеюсь, авторы данных блогов за анализ на меня не в обиде?
Подобный анализ проведите для своих блогов, и не только по данным копиям, но и по прочим, которые я приводил выше, таким как — category, tag и пр.
Ну как? Ваш результат вас порадовал?
Скорее всего не по всем данным словам вы найдете копии. Это конечно отлично! Но от тех, которые у вас имеются, придется избавиться! Давайте подумаем как?
Как убрать дубли страниц сайта решение проблемы
Во-первых , зайдите в мой роботс и скопируйте его себе, соответственно заменив сайт на название вашего сайта. Заменили? Отлично! Я думаю на многих блогах присутствовали запреты, как на сайте, приведенном выше.
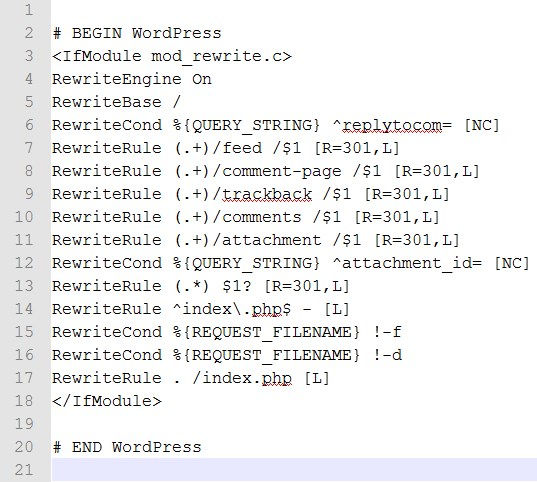
Во вторых , перепишите следующие строки в ваш файлик.htaccess:
 Данный файл находится в вашей корневой папке, которая чаще всего называется public_html. Для этого я обычно открываю программу , переношу нужный файл на рабочий стол, открываю данный файлик софтом Notepad + +, вношу необходимые изменения и заменяю старый файл на новый.
Данный файл находится в вашей корневой папке, которая чаще всего называется public_html. Для этого я обычно открываю программу , переношу нужный файл на рабочий стол, открываю данный файлик софтом Notepad + +, вношу необходимые изменения и заменяю старый файл на новый.
После закачки нового файла ваш.htaccess должен получиться примерно таким:
В третьих , вставляем в function.php после /*** ДОБАВЛЯЕМ meta robots noindex,nofollow ДЛЯ СТРАНИЦ ***/ function my_meta_noindex () { if (is_paged() // Все и любые страницы пагинации) {echo "".""."\n";} } add_action("wp_head", "my_meta_noindex", 3); // добавляем свой noindex, nofollow в head
В четвертых , проходим в расширение All in One Seo Pack и делаем так:


Если у вас другой плагин, например SEO, поставьте noindex в разделах, похожих по смыслу.
В пятых , в «Параметрах» идем в «Настройки-Обсуждения» и удаляем галку с пунктика Разбития комментариев:


В заключение предлагаю подробное видео про дубли.
На этом не всё, существует ещё множество дублей страниц и прочего хлама. Его необходимо удалять. Самому это не всегда сделать просто, поэтому иногда необходимо обращаться к профессионалу. Но его не всегда найдешь, да и не станешь постоянно обращаться.
Отсюда, желательно все тонкости узнать самому. Это можно сделать как при лично общении, так и изучив материал. Я имею в виду видеокурс. На мой взгляд, видеокурс предпочтительнее, т.к. вы пройдете обучение дама перед своим монитором!

Я не просто так привел данный курс, я его изучил. Мне лично он понравился. Раньше, Яндекс показывал у меня проиндексированных страниц 1220, хотя реально их 250. Сейчас, после очистки, Яндекс показывает 490, Гугл 530. Согласитесь, данные цифры ближе к реальным!
Но, как это не покажется странным, на большом количестве сайтов данные цифры зашкаливают за 200000 дублей и более. Без всяких шуток! Сайты с подобными показателями в скором времени могут быть забанены поисковиком. Но давайте вернемся к курсу. Приведу слова Александра:
Подробнее обо всём этом на сайте Борисова, для этого просто кликните по картинке с курсом.
В основном работа проделана, дубли страниц будут удалены после индексации, но не сразу, вам придется подождать несколько месяцев! Успехов в продвижении вашего ресурса! Если вам известны другие способы, как убрать дубли страниц сайта, пишите в комментариях, изучим вместе!
Анекдот в каждой статье.
 Мобильные телефоны Nokia
Мобильные телефоны Nokia Промокоды аптека ифк Описание магазина Аптека ИФК
Промокоды аптека ифк Описание магазина Аптека ИФК Голосование. Голосование Активный г
Голосование. Голосование Активный г Платные курсы по заработку в интернете - бесплатно!
Платные курсы по заработку в интернете - бесплатно! Настройка роутера ASUS RT N10P — подробная инструкция
Настройка роутера ASUS RT N10P — подробная инструкция Не открываются параметры компьютера - лечение Windows 10 не заходит в настройки
Не открываются параметры компьютера - лечение Windows 10 не заходит в настройки Изменение разделов жесткого диска с помощью Acronis Disk Director Как разбить жесткий диск разделы акронисом
Изменение разделов жесткого диска с помощью Acronis Disk Director Как разбить жесткий диск разделы акронисом